实战案例:用Trae开发一个Word文档合并工具
我计划创建一个Word文档合并工具,使用Python和Tkinter来构建GUI,使用docx和docxcompose库来处理Word文档合并。下面是对需求的详细拆解和实现步骤。

痛点识别
在日常工作中,文档合并的常见痛点包括:
1.格式丢失:复制粘贴时原有的字体、样式、表格格式经常丢失
2.文档标识困难:合并后难以区分内容来源
3.效率低下:处理大量文档时手工操作耗时巨大
4.顺序混乱:缺乏直观的排序机制
解决方案设计
基于这些痛点,我们的解决方案需要具备:
1.直观的图形界面:降低使用门槛
2.拖拽排序功能:便于调整文档顺序
3.格式保持能力:确保合并后格式不丢失
4.文档标识机制:自动标注每个文档的来源
5.批量处理能力:支持一次处理多个文档
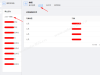
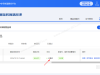
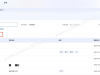
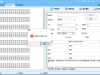
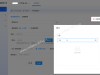
功能需求 1.文档选择: 用户可以通过按钮添加多个.docx文件。 文件列表以表格形式显示(序号、文件名、大小)。 支持移除选中文件、上移、下移、置顶、置底和清空操作。 2.输出设置: 用户可以指定保存目录(通过浏览按钮选择)。 用户可以指定合并后的文件名(默认为“合并后文档”)。 合并选项:是否在每个文档前插入分页和文件名(加粗、居中、16磅)。 3.操作按钮: 访问官网:打开指定网站。 开始合并:执行合并操作(在后台线程中执行,避免界面冻结)。 退出程序:关闭应用。 4.状态显示: 进度条显示合并进度。 状态栏显示当前状态信息。 5.合并功能: 合并时保留第一个文档的页面设置(页面方向、页边距等)。 若勾选选项,则在每个文档前插入新页并添加原文件名(作为标题,格式为加粗、16磅、居中)。 合并完成后自动打开保存目录。
技术实现
1.GUI框架:Tkinter(包含ttk用于进度条和Treeview)。
2.文档处理:使用docx库读取和创建Word文档,使用docxcompose库的Composer合并文档(注意:Composer不是标准库,需要安装docxcompose)。
3.多线程:使用threading模块在后台执行合并任务,避免界面卡顿。
4.文件操作:使用os模块处理文件路径和大小。
注意点- 页面设置:合并时使用第一个文档的页面设置(包括方向、页边距等)。
- 插入文件名:如果勾选,则在每个文档前插入新页,并在新页上添加文件名(居中、加粗、16磅)。
- 进度更新:在合并过程中更新进度条和状态信息,注意在Tkinter中通过update_idletasks刷新界面。
- 异常处理:捕获合并过程中的异常,并通过消息框提示用户。
- 文件覆盖:如果目标文件已存在,询问用户是否覆盖。
文件名为“Word文档合并工具_独立分页_命令行.py”,代码为:
- import os
- import copy
- from docx import Document
- from docx.enum.section import WD_SECTION # 新增:导入分节符枚举
- from docx.enum.section import WD_ORIENT
- from docx.oxml.shared import qn
- from docx.shared import Pt
- from tqdm import tqdm
- from docxcompose.composer import Composer # 补充缺失的合并器导入
- # 文件扫描与筛选(顶级代码块需顶格,无缩进)
- all_files = [f for f in os.listdir('.') if f.endswith('.docx')]
- source_files = [f for f in all_files if not f.lower().startswith('merged')]
- source_files.sort()
- def merge_word_documents(input_files, output_file, delete_after_merge=False):
- """合并多个 Word 文档为一个文档(每个文档前插入分页符)"""
- try:
- # 检查输入文件列表
- if not input_files:
- print("错误: 没有提供要合并的文件")
- return False
-
- # 读取首个文档以获取页面设置
- first_source_doc = Document(input_files[0])
-
- # 初始化目标文档(保持原代码不变)
- target_doc = Document()
-
- # 复制首个文档的页面设置(方向、页边距等)
- target_section = target_doc.sections[0]
- source_section = first_source_doc.sections[0]
-
- target_section.orientation = source_section.orientation
- target_section.page_width = source_section.page_width
- target_section.page_height = source_section.page_height
-
- # 复制页边距设置
- target_section.left_margin = source_section.left_margin
- target_section.right_margin = source_section.right_margin
- target_section.top_margin = source_section.top_margin
- target_section.bottom_margin = source_section.bottom_margin
-
- # 初始化合并器
- composer = Composer(target_doc)
-
- # 逐个合并文档(首个文档不插分页符,后续文档前插入)
- for index, doc_path in enumerate(input_files):
- current_doc = Document(doc_path)
- # 从第二个文档开始,每个文档前插入分页符
- if index > 0:
- composer.doc.add_section(WD_SECTION.NEW_PAGE) # 插入新页
- composer.append(current_doc)
-
- # 保存合并后的文档(使用传入的output_file参数)
- composer.save(output_file)
- print(f"成功合并 {len(input_files)} 个文档到: {output_file}")
-
- # 可选: 删除原始文件
- if delete_after_merge:
- for file in input_files:
- os.remove(file)
- print(f"已删除: {file}")
-
- return True
-
- except Exception as e:
- print(f"合并过程中发生错误: {str(e)}")
- return False
- if __name__ == "__main__":
- # 调用合并函数,传入扫描得到的文件列表和输出路径
- merge_word_documents(source_files, "merged.docx")
- print("文档合并完成,结果保存为merged.docx")
在命令行代码的功能上又添加了图形界面,最终发布为exe可执行文件,下载地址:
|  |Archiver|手机版|小黑屋|管理员之家
( 苏ICP备2023053177号-2 )
|Archiver|手机版|小黑屋|管理员之家
( 苏ICP备2023053177号-2 )


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡